About
I'm a PhD student in Artificial Intelligence at MICC, University of Florence, advised by Prof. Andrew D. Bagdanov and Prof. Marco Bertini.
I recently completed an Applied Scientist Internship at Amazon (RufusX Team, London), developing large-scale multimodal generative models (MLLMs) for the Amazon Rufus initiative, impacting millions of users worldwide.
Research Interests
My research focuses on Multimodal Vision-Language Models (VLMs) like CLIP and their practical applications. I work on fundamental problems in:
- Multimodal Representation Learning: Understanding and bridging modality gaps in vision-language models
- Prompt Learning & Knowledge Distillation: Improving zero-shot generalization without labeled data
- Continual Learning: Enabling models to learn incrementally while preventing catastrophic forgetting
- Few-Shot & Test-Time Adaptation: Efficient model adaptation with minimal supervision
Key Contributions
I have published 4 top-conference papers:
- CVPR 2026 (main conference) — Decomposing CLIP projectors to reveal inter- and intra-modal alignment
- ICLR 2026 (main conference) — Spectral concept selection for generalized category discovery via CLIP
- ICLR 2025 (main conference) — Exposing intra-modal misalignment in CLIP via modality inversion
- ECCV 2024 (main conference) — Unsupervised prompt learning via knowledge distillation
My work advances the state-of-the-art in vision-language understanding and has practical applications in medical imaging, open-vocabulary recognition, and continual learning systems.
News
-
Feb, 2026
A paper on intra-modal alignment in CLIP is accepted at CVPR 2026.
-
Jan, 2026
A paper on generalized category discovery is accepted at ICLR 2026.
-
Jul 2025 – Dec 2025
Internship at the Amazon RufusX team in London.
-
Jan, 2025
A paper on multimodal VLMs representation is accepted at ICLR 2025.
-
Sep, 2024
Presented a paper on prompt learning at ECCV 2024.
-
Aug, 2024
KDPL source code is finally available!
-
Dec, 2023
Presented a paper on continual learning at NeurIPS 2023 (workshop).
Recent Publications
-
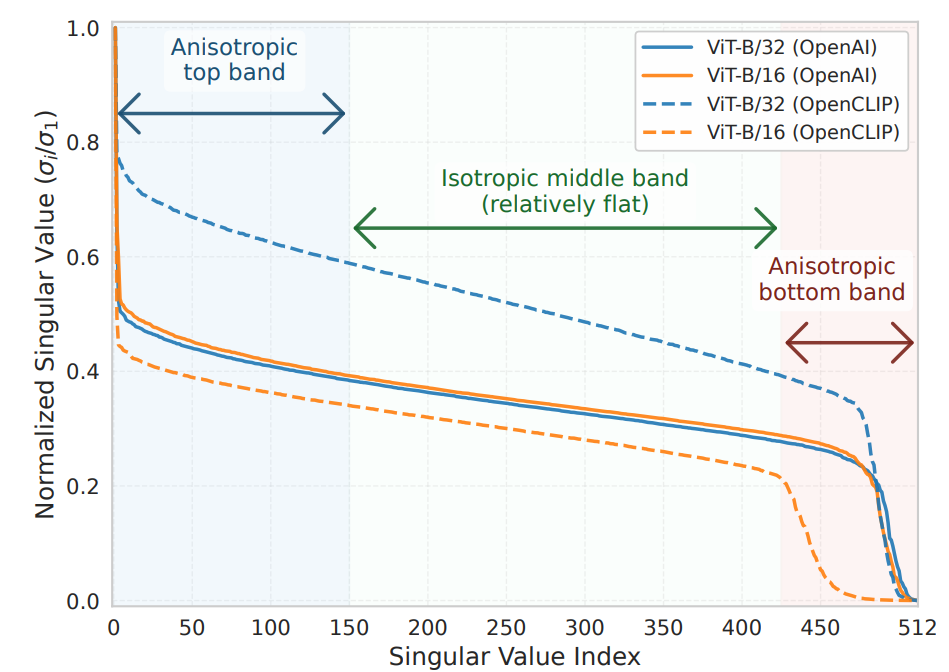
IsoCLIP: Decomposing CLIP Projectors for Efficient Intra-modal Alignment
Magistri S., Goswami D., Marco Mistretta, Twardowski B., van de Weijer J., Andrew D. Bagdanov
-
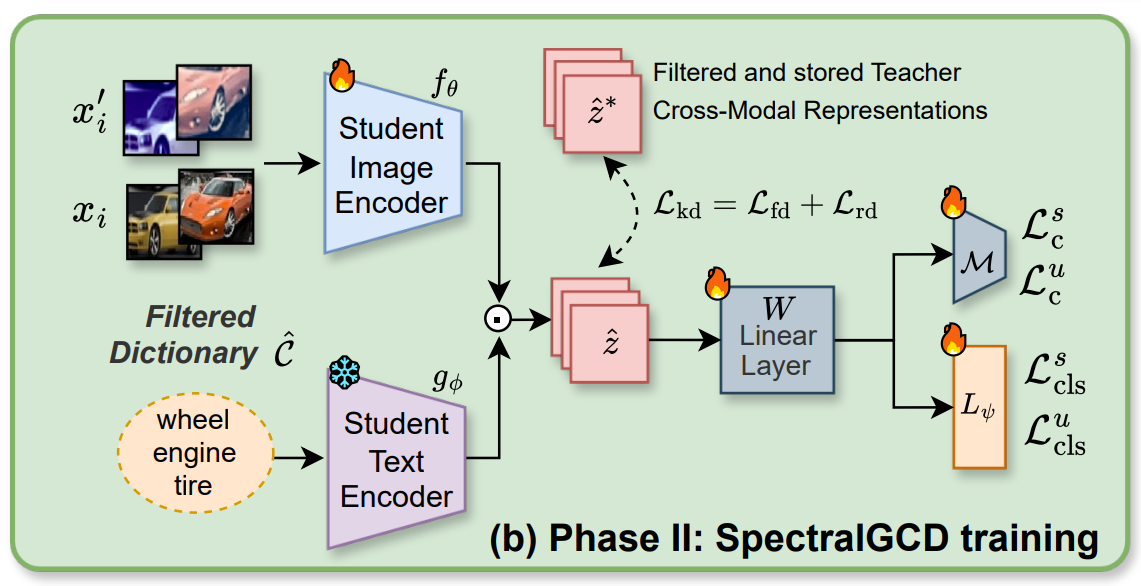
SpectralGCD: Spectral Concept Selection and Cross-modal Representation Learning for Generalized Category Discovery
Caselli L., Marco Mistretta, Magistri S., Andrew D. Bagdanov
-
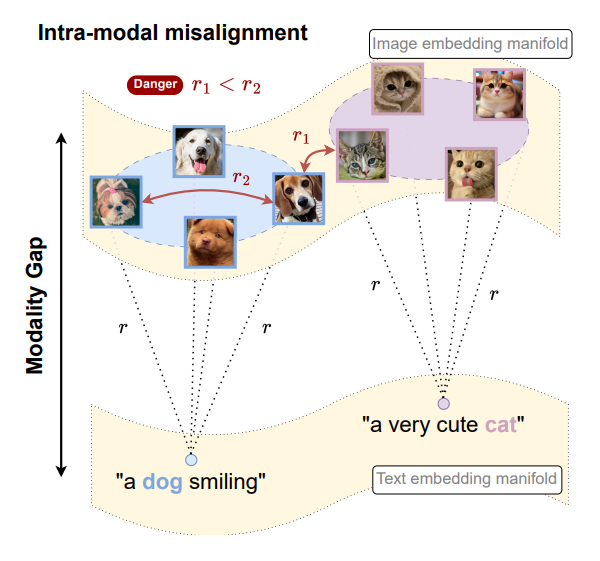
Cross the Gap: Exposing the Intra-modal Misalignment in CLIP via Modality Inversion
Marco Mistretta, Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, Andrew D. Bagdanov
-
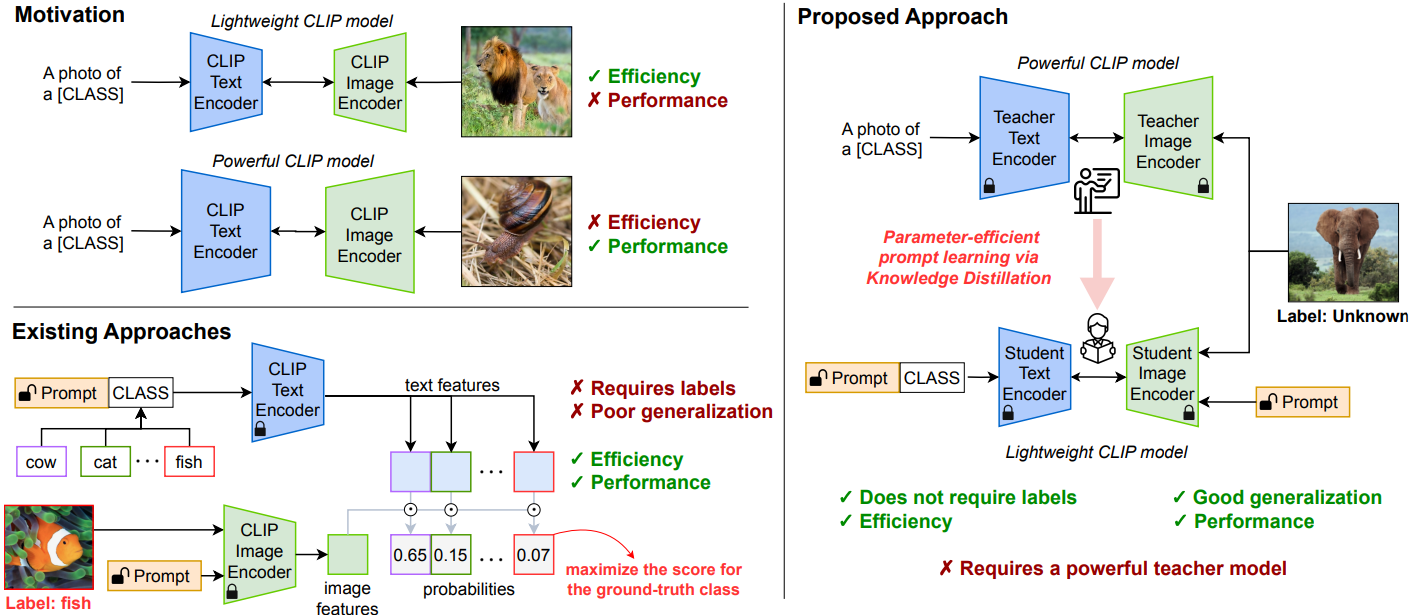
KDPL: Improving Zero-shot Generalization of Learned Prompts via Unsupervised Knowledge Distillation
Marco Mistretta, Alberto Baldrati, Marco Bertini, Andrew D. Bagdanov
-
RE-tune: Incremental Fine Tuning of Biomedical Vision-Language Models for Multi-label Chest X-ray Classification
Marco Mistretta, Andrew D. Bagdanov
Work Experience
-
July 2025 — December 2025 Applied Scientist Intern – Amazon (RufusX Team, London)
Applied Scientist Intern – Amazon (RufusX Team, London)
Worked on Generative AI and Multimodal Large Language Models (MLLMs) as part of the Amazon Rufus initiative. Fine-tuned, evaluated, and deployed large-scale multimodal models impacting millions of customers, advancing multimodal reasoning and generation at scale.
Education
-
PhD student in Artificial Intelligence
Nov, 2023 — PresentUniversity of Florence, Florence, Italy
Topic: Multimodal Vision-Language Models, Incremental Learning, Prompt Learning.
-
M.S. in Artificial Intelligence
Sep, 2021 — Jul 2023University of Florence, Florence, Italy
Thesis: "RE-Tune - Incremental Fine-Tuning of Biomedical Vision-Language Models"
-
B.S. in Computer Science and Engineering
Sep, 2018 — Sep, 2021University of Florence, Florence, Italy
Thesis: "Scarlatti-Gen - AI-Driven Sonata Generation Using Weighted Graphs and CNNs"
Teaching and Mentoring
-
Teaching Assistant, University of Florence
Delivering interactive lessons on C/C++ and Python to over 200 bachelor students.
Jan 2024, Jan 2025 -
Thesis Co-Supervisor, University of Florence
Apr 2024, Sep 2024"Mitigating Catastrophic Zero-shot Forgetting in CLIP via Distillation of Low-Rank Adapters from Learned Prompts", Proposed a novel method to efficiently few-shots fine-tune CLIP models that mitigates catastrophic forgetting and preserves zero-shot capabilities, based on distilling learned prompts in LoRa adapters.
-
Student Ambassador, University of Florence
Jan 2020, Dec 2020Mentoring students on exams projects, internships, and career development.
